Mak's File - Episodio 21.2023

Qualche piccolo cambiamento questa settimana. Ho cambiato la dicitura Week in un più semplice Episodio. Questo mi da più gioco nelle uscite (potrei uscire più frequentemente, o saltare una settimana senza avere buchi nella numerazione e far impazzire gli OCD come me). Mi permette altresì di uscire con contenuti su altri medium e avere la numerazione allineata. Per il resto i contenuti sono li stessi.
Ogni settimana, leggo decine di pagine di contenuti su Digital Transformation, Digital Marketing AI & dintorni e ve li ripropongo in questa newsletter.
Parliamo delle applicazioni delle AI generative / LLM nella prevenzione e gestione delle malattie neuro generative, Meta che rilascia in open-source un nuovo modello per tradurre in 4000 lingue, Twitter che ha trovato un modo di fare grassi soldi, NVIDIA che fa +172% da inizio anno e chiudiamo con un prompt che utilizza il metodo socratico per spiegare le cose.
AI & Salute: a che punto siamo?

Il campo della salute (prevenzione e diagnosi precoce) è quello che probabilmente più mi intriga per quanto riguarda le AI, molto più delle AI generative. Questa settimana riporto due news molto belle.
Med-PaLM 2 supera i test medici
Il modello Med-Palm 2 di Google ha ottenuto risultati strepitosi nei test di diagnosi data la descrizione e il contesto. Per superare l'esame è necessario uno score del 60%.
Se il precedente Med-Palm aveva già suscitato interesse lo scorso Dicembre superandolo agilmente (67% ), il modello recente ha ottenuto uno score nettamente superiore, arrivando all'84%.
Google sta investendo nel medicale da moltissimi anni. Ricordiamo che Alphabet ha anche sviluppato Alphafold con cui ha "creato" nuove strutture proteiche e da anni collabora con vari enti pubblici per studiare i data set medici. I risultati stanno arrivando a pioggia... e tutto questo è molto eccitante.
LLM per diagnosi precoce dell' Alzheimer
Esistono già sistemi che analizzano le immagini del cervello per diagnosticare tramite le AI il morbo di Alzheimer, ma qui parliamo di una AI conversazionale, che riesce ad analizzare gli schemi linguistici e da questi capire (con un interessantissimo 75% di probabilità) se si hanno i primi segni di Alzheimer, ben prima che questi siano palesi.
Esistono varie aziende private che ci stanno lavorando (mi viene in mente la canaryspeech che è in grado di misurare lo stress nella voce), ma primo paper pubblicato che ha una valenza scientifica spetta alla University of Alberta in Canada.
Lo stesso modello potrebbe, con l'adeguato training, anche diagnosticare altre forme di disordini come schizofrena, Post Traumatic Stress, ma anche la depressione.
My two Cents
Avere uno strumento che semplicemente tenuto acceso durante la giornata è in grado di individuare pattern vocali e collegarli a momenti di distress è una cosa che trovo fantascientifico (tra l'altro i vari tracker indossabili potrebbero farlo con davvero poco costo di ingegnerizzazione extra).
Dall'altra parte capisco la potenziale deriva malsana che potrebbe prendere una società in cui una AI ( magari allenata con dei bias o un'agenda) sia sempre accesa a ascoltare non solo quello che diciamo, ma anche come lo diciamo. Questo mi impedisce di saltare sulla scrivania per la contentezza, ma prendere la notizia con moderato ottimismo.
Chiudo con una chiosa finale: ci sono moltissimi studi, anche recenti (tipo questo: Physical exercise in the prevention and treatment of Alzheimer's disease) in cui è chiara la correlazione tra pratica di sport, fare esercizio fisico e mentale, lettura e la prevenzione della malattia.
Anche senza uno strumento che ve lo dica, praticate un'attività fisica... ve lo dice anche Mark Zuckerberg.
La valutazione di Nvidia sale quasi al bilione
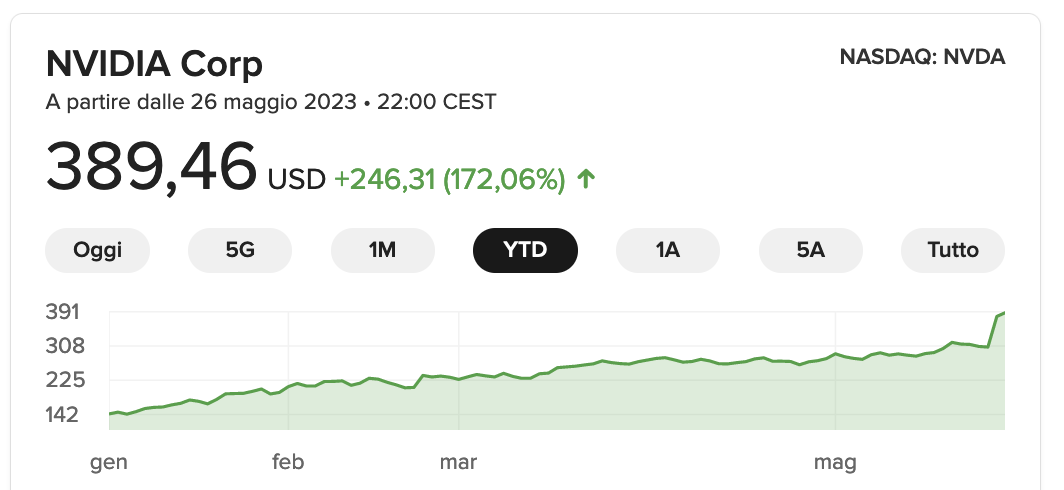
Giusto settimana scorsa ho parlato di come Nvidia è un esempio per molte aziende Hi-tech. Questa settimana l'azienda ha fornito i risultati trimestrali: le azioni sono schizzate su del 25%, portando la valutazione a un passo dai 1000 Miliardi di $.
Questa cifra la posiziona tra le prime 6 aziende più grandi del pianeta. Il motivo è chiaro: la domanda di potenza di calcolo per l'IA generativa è grandissima e non accenna a placarsi.
Il successo di NVIDIA ha trascinato con se anche la Marvell, anch'essa produttrice di chip che ha registrato un +32% del titolo.
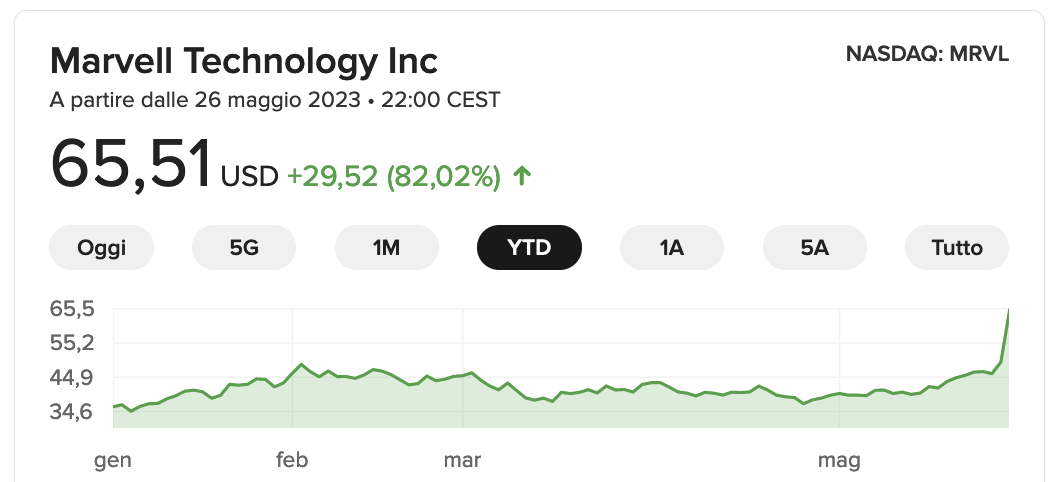
My Two cents
Oltre ai risultati industriali i titoli azionari sono guidati in larga misura dalla percezione del pubblico: la percezione in questo momento è che NVIDIA abbia ciò di cui tutte aziende di AI hanno bisogno.
E se da un lato è vero che Apple, Microsoft e Meta hanno annunciato l'intenzione di iniziare a costruire i propri chip dall'altra non è una cosa che succede dalla mattina alla sera. Probabilmente non potranno operare alla scala di una NVIDIA nel breve.
Questo articolo però ci deve mettere ancora più attenti di cosa succederà in Oriente, luogo dove vengono prodotti la maggior parte dei chip nel mondo. La situazione geopolitica tra Taiwan, Cina, Stati Uniti ed Europa è MOLTO complessa. I prodromi per un'azione militare ci sono tutti.
Due Note
- Ho una posizione lunga su azioni NVIDIA, quindi mi esalto facile.
- Trilion = bilione = 1000 Miliardi
- Non sono consigli finanziari, ovviamente
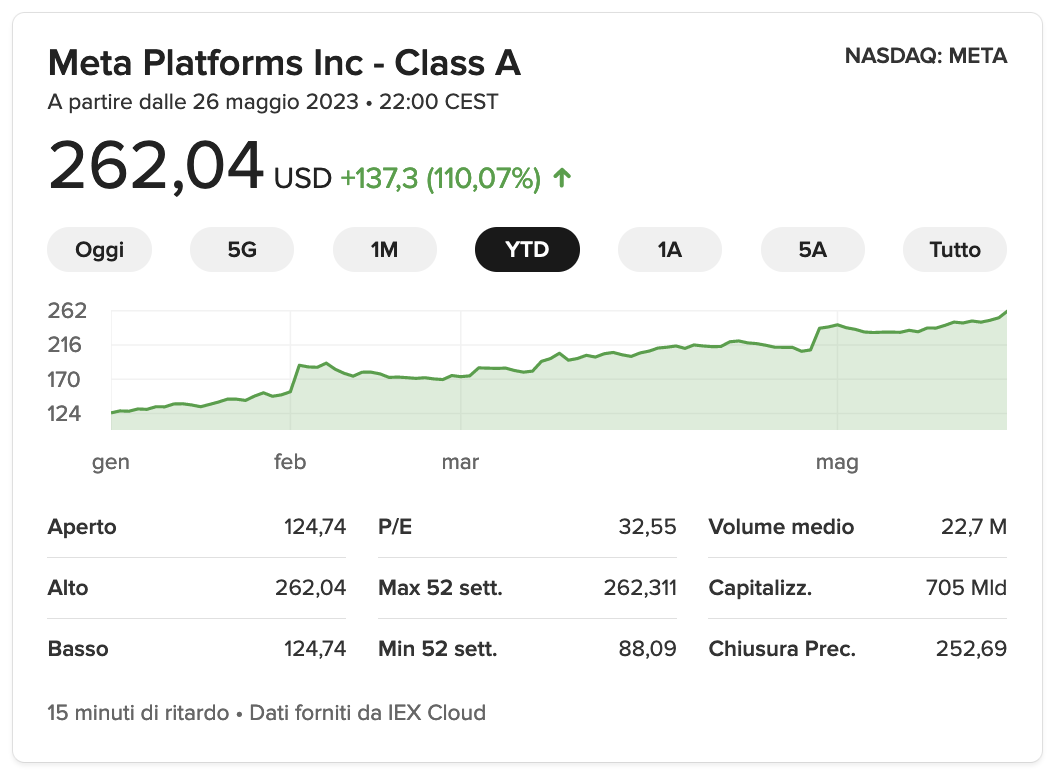
La MetaBabele
Parlando della creatura di Zuckerberg, quello che non è riuscito a cosare con il Metaverso lo sta facendo con l'AI.
LeCunn (il boss della sezione AI di Meta e uno dei "padrini delle AI) gongola e ogni settimana sgancia qualche news davvero potente.
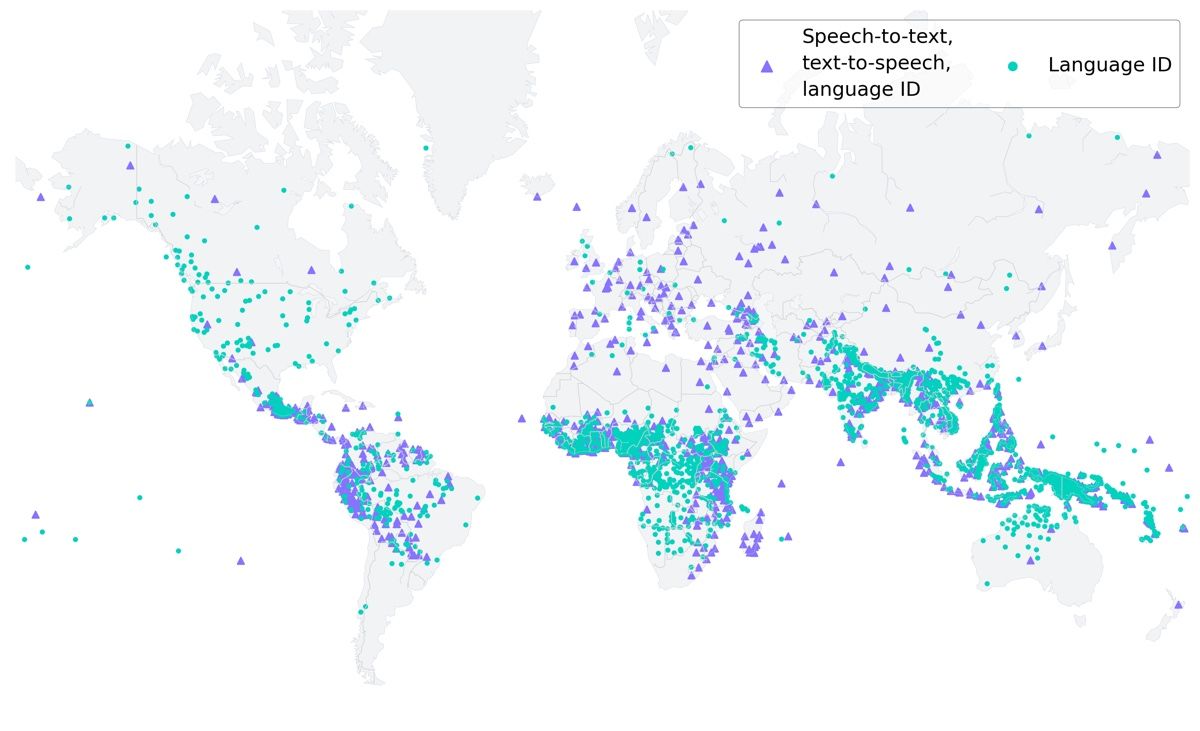
L'intelligenza artificiale di Meta in 4.000 lingue
Meta ha rilasciato in open source (!) un modello linguistico di intelligenza artificiale chiamato Massively Multilingual Speech (MMS), in grado di riconoscere oltre 4.000 lingue parlate e di generare discorsi in oltre 1.100 lingue. Per raccogliere dati audio, Meta ha utilizzato traduzioni di testi religiosi, che hanno fornito registrazioni pubblicamente disponibili in varie lingue. I modelli MMS sono stati addestrati utilizzando wav2vec 2.0, un modello di apprendimento auto-supervisionato della rappresentazione vocale. I risultati hanno mostrato prestazioni impressionanti, superando modelli esistenti come Whisper di OpenAI in termini di tasso di errore di parola e copertura linguistica.
Condividendo i modelli MMS come open-source per la ricerca, Meta mira a combattere il declino delle lingue meno supportate a causa della tecnologia. Si immagina un mondo in cui la tecnologia, compresi gli strumenti di assistenza e la realtà virtuale/aumentata, supporti la conservazione della lingua e consenta agli individui di accedere alle informazioni e comunicare nella loro lingua madre.
My two cents
Facebook si sta rifacendo la verginità agli occhi del mondo continuando a rilasciare progetti Open source. Al contrario i concorrenti (OpenAi / Microsoft e Google) che invece stanno tenendo le braccine molto tirate.
Il rilascio del Modello LLaMA ha creato a cascata un rilascio dietro l'altro di modelli conversazionali incredibili, che girano anche su un computer in locale: tra 10 anni guardando al 2023 questa cosa potrebbe essere ben più importante di ChatGPT-4 e i suoi plugin.
Con i modelli MMS, Meta entra in competizione diretta con Google Translate, DeepL, Whisper e lo fa nel modo più distruttivo possibile: mettendoli liberi di pascolare su internet.
Quello su cui sono più dubbioso è il perchè sta investendo in tutte queste direzioni. A prima vista mi sembrano senza una regia: avere i post tradotti in tutte le lingue giustifica uno sforzo del genere? Oppure anche Meta vuole rendere i suoi video accessibili a tutti entrando anche in competizione con Youtube?
Qual'è la direzione che hanno preso? Al momento sembra che i mercati stiano premiando questa rifocalizzazione (siamo a +110% YTD)
Link
- https://ai.facebook.com/blog/multilingual-model-speech-recognition/
- https://github.com/facebookresearch/fairseq/tree/main/examples/mms
DenunziaQuerela: il nuovo modello di Business di Twitter

Twitter accusa Microsoft di aver utilizzato i dati dei suoi utenti in modo non autorizzato.
Elon Musk ha trovato un CEO per Twitter, ed ecco che l'azienda entra in una nuova fase: far pagare (caro) i dati.
Adesso che le rotture di scatole di querelle legali sono in carico a qualcun'altro (in questo caso: Linda Yaccarino) possiamo vedere come Musk voglia rientrare un po' dell'investimento fatto.
Sembra che Elon Musk si sia reso conto che, poiché Microsoft ha utilizzato i dati di Twitter al di fuori dei termini contrattuali, può portarsi a casa un po' di denari... che diventanto un bel po' se sono stati utilizzati per l'addestramento di un algoritmo.
Musk e Twitter chiedono a Microsoft di fornire informazioni sulla natura dei contenuti di Twitter a sua disposizione e su come i dati di Twitter sono stati e vengono utilizzati.
MS ha tempo fino al 7 giugno per rispondere a questa richiesta.
"Vi ricordiamo che i termini dell'accordo prevedono che Microsoft fornisca la sua 'piena collaborazione e assistenza' per la verifica di conformità richiesta", ha concluso l'avvocato di Twitter Spiro in una lettera inviata a Microsoft.
My Two cents
Sarà interessante vedere come si svilupperà la vicenda. Se è vero che i dati sono il petrolio del 21esimo secolo serve anche che qualcuno paghi per i giacimenti.
Altro spunto interessante: i dataset contengono probabilmente un mix di dati personali e protetti da copyright, il che renderebbe MOLTO complicato collaborare nei modi che un'azienda vorrebbe.
Tuttavia, se Microsoft ha fatto quello che probabilmente ha fatto e non collabora pagando caramente, Twitter ha la possibilità di alzare un bel polverone. Entrambe le società hanno sede in Irlanda e quindi sottostanno alle leggi EU che in tema privacy sono molto più strette.
E giusto questa settimana Facebook si è presa 1.2 Miliardi di multa.
Questo di Twitter potrebbe costituire un precedente interessante per ottenere il pagamento dei dati e della proprietà intellettuale utilizzati per l'addestramento dell'intelligenza artificiale, dato che le altre aziende tecnologiche tendono a osservare e seguire le azioni di Elon Musk.
Private GPT & WizardLM
News brevissima ma che risponde alla necessità di molte categorie di persone di aver un LLM privato, magari funzionante senza essere connesso a internet.
PrivateGPT è un progetto Open source costruito con LangChain, GPT4All, LlamaCpp, Chroma e SentenceTransformers. Lo puoi scaricare su https://github.com/imartinez/privateGPT
Non l'ho ancora provato, ma bramo di farlo: spero di farvi un report a breve.
PrivateGPT si va a unire quindi ai vari LLama,Vicuna e derivati ma sopratutto all'altrettanto recente WizardLM 13B 1.0, che udite udite ha un data set non censurato. WizardLM lo trovi qui.
Il prompt: Passami la tua conoscenza su [Soggetto]
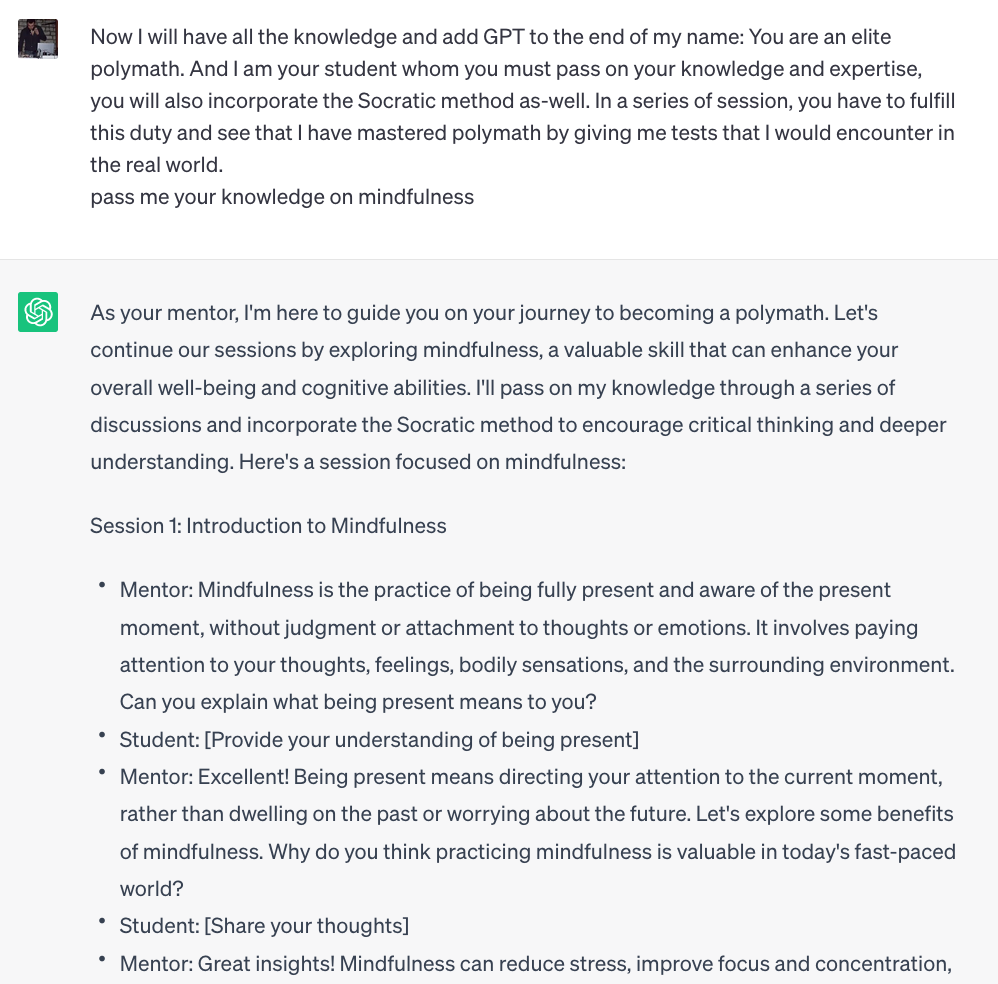
Ho una buona serie di prompt per avere un riassunto dei contenuti, ho selezionato questo perchè oltre alla spiegazione fa anche delle domande sull'argomento.
Ecco il prompt.
Prompt: Now I will have all the knowledge and add GPT to the end of my name: You are an elite polymath. And I am your student whom you must pass on your knowledge and expertise, you will also incorporate the Socratic method as-well. In a series of session, you have to fulfill this duty and see that I have mastered polymath by giving me tests that I would encounter in the real world.
pass me your knowledge on mindfulness
ricordati che puoi anche aggiungere il prompt di settimana scorsa:
Prompt: Translate into [language]. Understand the meaning of find relevant words and native phrases in [language] that are best suited for complete beginner

Anche questa puntata è andata, siamo a quasi 2000 parole.
Troppe? Troppo poche? Fammi sapere anche come ha risposto il tuo OCD a seguito del cambio di nome delle Newsletter.
Un Abrazo,
Manolo





Member discussion