Episodio 54.2025

Altro episodio che ho scritto, lasciato maturare, cancellato in buona parte perché le notizie erano scadute e riscritto, in tutto questo ho scoperto come creare il sommario con Ghost e quindi da questo episodio puoi vedere da subito di cosa andrò a parlare.
Elon Musk offre 97.4 Miliardi per OpenAI non profit. Sam Altman rifiuta (ovviamente): diamo una lettura diversa dal solito.
Partiamo dall'accadimento Elon Musk offre 97.4 Miliardi per OpenAI, Sam Altman risponde picche e rilancia: ti compro Twitter per 9.7 Miliardi (un quarto di quanto l'ha pagata Musk).
My two cents
Al netto del simpatico siparietto ((simpatico "like a cat hanging to your ballz" direbbe qualcuno). Leggiamo con un po' meno bias dell'hater medio cosa potrebbe essere successo.
Prima cosa: riformuliamo l'headline.
Scriverei qualcosa tipo "Una cordata di imprenditori con a capo Musk propone l'acquisto della parte no-profit di OpenAI a 97 Miliardi"
Secondo: dove ha trovato i soldi Musk per questo offerta?
Uno dei nomi usciti è Ari Emanuel. Ari è sostenitore dei DEM, ma amico personale di lunga data di Donald Trump. E' anche il boss di TKO Group Holdings, che possiede i brand WWE e UFC.
E chi è il Boss di UFC? Dana White - che ricordiamo essere uomo di Trump, e recente new entry nel board di Meta probabilmente proprio per questo motivo.
Questa notizia è parzialmente superflua per il discorso che andremo a fare, ma ho la sensazione che tra qualche mese questa sarà un mattone importante di qualche discussione, quindi la lasciamo maturare qui.
Terzo: rifiutando i 97 Miliardi aumenta il valore di OpenAI.
Ricordate qualche post fa dove vi descrivevo della cordata con a capo OpenAI e Softbank con lo scopo di acquistare il ramo di no-profit e incorporarlo nella sezione for-profit? Indiscrezioni davano il valore di acquisizione di 40 miliardi. Rifiutandone più del doppio Altman e gli altri si espongono pensatemente sulle accuse future dei vari shareholder nel caso l'investimento non rientri.
OpenAI continua a bruciare tanto denaro e la sua profittabilità è lontana. Tutti sono ancora felici di investire nell'azienda... ma se le cose non si sistemano e tra 3-4 anni qualcuno si lamentasse della condotta del management, siamo sicuri che nessuno esca per recriminare questo rifiuto? Questo senza contare azioni d'ufficio degli organi competenti ovviamente.
Musk ha quindi giocato d'astuzia, obbligando OpenAi for profit a spendere molti più soldi per acquisire un ramo d'azienda proprio.
Quarto: tutti abbiamo dato del trimone a Musk per quanto ha pagato Twitter. Ma gli stupidi siamo noi.
Musk ha pagato con soldi a debito uno dei media più importanti del mondo. Grazie a questo ha fatto vincere le elezioni a Trump e finchè durerà la bromance gli danno carta bianca di fare quello che vuole.
Il valore delle azioni Tesla è - nonostante tutto - salito tantissimo: Musk si è ritrovato con molti più soldi di quanto avrebbe avuto pre-acquisto.
Oltre a questo pur avendo licenziato il 75% della forza lavoro X / Twitter si è ripresa anche coi fatturati. I ricavi pre tasse si attestano intorno al 50% della gestione precedente. Considerando che magicamente il social network non è più per appestati come sembrava qualche mese fa e si iniziano a vedere aziende che investono in pubblicità... direi che Elon ha superato il guado.
Attenzione non sto esaltando il figuro (molte delle sue scelte recenti in fatto di tagli hanno solo una definizione: criminali), ma vorrei che almeno noi, almeno qui riuscissimo a separare la narrazione dalla realtà
Zuckerberg è Gol D Roger Travestito.
Meta ha scaricato 82TB di libri piratati per addestrare l’AI: emergono violazioni di copyright

Meta, la società madre di Facebook, è attualmente coinvolta in una class action per violazione del copyright e concorrenza sleale, con particolare riferimento al modo in cui ha addestrato LLaMA. Secondo un post su X (ex Twitter) di vx-underground, i documenti del tribunale rivelano che l’azienda ha utilizzato torrent piratati per scaricare 81,7TB di dati da librerie ombra come Anna’s Archive, Z-Library e LibGen, poi impiegati per addestrare i suoi modelli di intelligenza artificiale.
Le prove, sotto forma di comunicazioni scritte, mostrano come alcuni ricercatori interni fossero preoccupati per l’uso di materiale piratato. Già nell’ottobre 2022, un senior AI researcher scriveva: “Non penso che dovremmo usare materiale piratato. Devo davvero tracciare un limite qui.” Un altro dipendente aggiungeva: “Usare materiale piratato dovrebbe essere al di là della nostra soglia etica.” Citava poi piattaforme come SciHub, ResearchGate e LibGen, paragonandole a “una sorta di PirateBay”, sottolineando come distribuissero contenuti protetti da copyright.
Meta e il dubbio dell’etica
Nel gennaio 2023, Mark Zuckerberg partecipa a un meeting interno e afferma: “Dobbiamo far avanzare questa cosa… dobbiamo trovare un modo per sbloccare tutto questo.” Tre mesi dopo, un dipendente di Meta scrive a un collega esprimendo preoccupazione per l’uso di indirizzi IP aziendali per accedere a contenuti piratati: “Scaricare torrent da un laptop aziendale non sembra giusto”, accompagnando il messaggio con un’emoji che ride.
I documenti rivelano anche che Meta avrebbe adottato misure per evitare che le operazioni di download e seeding fossero ricondotte alla propria infrastruttura, cercando così di non lasciare tracce. Il tribunale interpreta queste azioni come prova di un’attività illecita deliberata per aggirare le leggi sul copyright.
Non solo Meta: il problema del copyright nell’addestramento AI
Meta non è l’unica ad affrontare accuse simili. Nel giugno 2023, OpenAI è stata denunciata da alcuni scrittori per l’uso non autorizzato dei loro libri per addestrare i modelli di linguaggio. A dicembre, anche il New York Times ha intentato una causa contro l’azienda. Nvidia, dal canto suo, è stata accusata di aver utilizzato 196.640 libri per addestrare il modello NeMo, successivamente rimosso. Nell’agosto 2023, un ex dipendente Nvidia ha denunciato che la società stava raccogliendo oltre 426.000 ore di video al giorno per il training AI.
Più di recente, OpenAI sta investigando se DeepSeek abbia ottenuto illegalmente dati da ChatGPT, un’ironia non da poco in questo scenario.
Cosa succederà ora?
Il processo contro Meta è ancora in corso e bisognerà attendere la sentenza per capire se l’azienda verrà ritenuta responsabile di violazione diretta del copyright. Anche nel caso di una condanna, Meta dispone di risorse finanziarie enormi e con ogni probabilità ricorrerà in appello, allungando i tempi della disputa legale di mesi, se non anni.
L'Etica nelle AI: OpenAI accusa DeepSeek di aver sottratto dei dati dai suoi modelli. Le implicazioni sono molto maggiori di quello che sembra.

Per prima cosa scusami se ho frammato questo articolo, decisamente importante, con un meme: è una cosa sciocca da fare, ma mi diverto così.
OpenAI ha accusato DeepSeek—il nuovo concorrente cinese in ascesa nel settore dell’intelligenza artificiale—di aver utilizzato un processo chiamato distillazione per incorporare le capacità dei modelli di OpenAI nel proprio addestramento. In altre parole, OpenAI ha sollevato il dubbio che DeepSeek abbia sottratto dati dai suoi modelli.
Non è chiaro se sia davvero così, ma la questione ha fatto notizia.
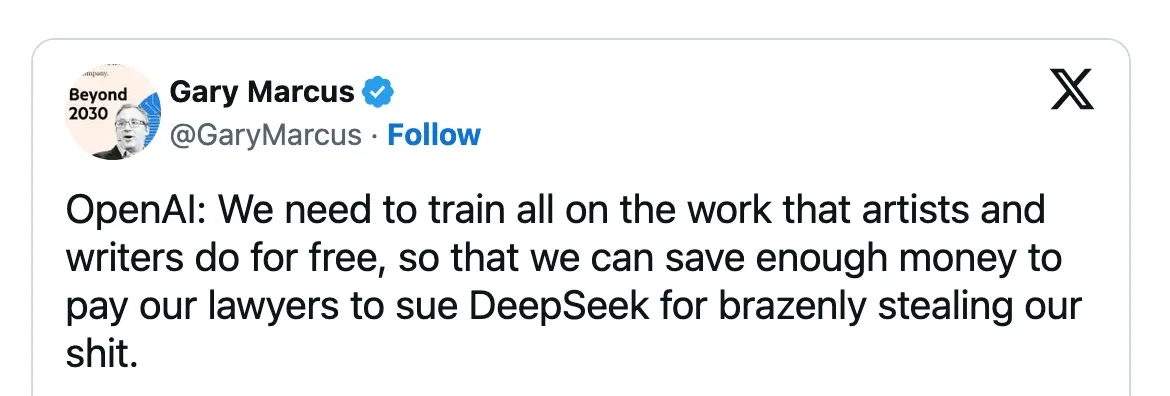
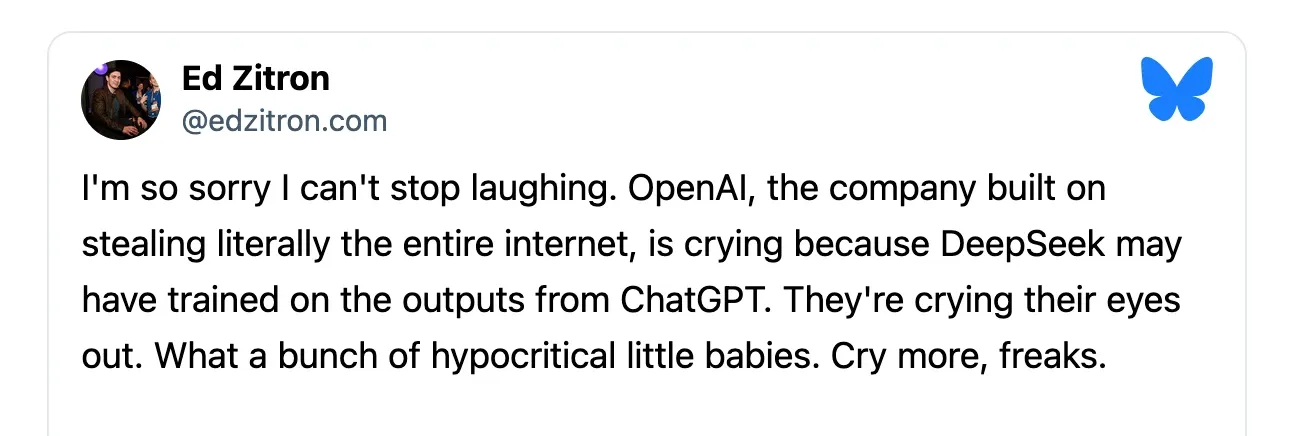

Ne sono nati meme e ovviamente tantissimi commenti divertiti, visto che sembra che anche OpenAI abbia costruito il proprio business rastrellando l’intero web per addestrare i suoi modelli.
Alcune cause legali sostengono persino che ChatGPT riproduca informazioni protette da copyright alla lettera.
My two cents
Sembra che il mondo in cui una parte può rubare impunemente agli altri sia finito: questo perchè adesso E' CHIARO che chiunque col borsello abbastanza largo può rubare a chiunque impunemente. Questo apre dei problemi etici e di business.
Ti lascio delle domande, senza risposte. Così a germogliare a fuego lento.
- In che modo un investimento massiccio in AI generative può essere difeso se dopo qualche mese esce un modello molto simile a un decimo del costo?
- Come si può valutare un’azienda che accusa un’altra di comportamenti simili a quelli che l’hanno resa dominante? È un segnale di ipocrisia oppure sono davvero accecati dalla loro sicumera?
- Perchè nonostante tutto, nessuno lavora pubblicamente per ridistrubuire la ricchezza anche verso chi ha creato i contenuti originari (autori di libri)?
- Parlando di dati, Quali saranno le prossime fonti di addestramento?
- Se una AI può allenare un'altra AI, dove è il limite tra distillazione di dati e fellatio-reciproca-circolare-infinita ?
- Se una AI può allenare un'altra AI esistono dei safeguard su "mutazioni" di codice non previste?
- Se c'è una corsa al ribasso verso sicurezza ed etica... siamo sicuri che è una gara a cui vogliamo (come Europa, come mondo) partecipare?
Se vai avanti a leggere ti parlo di ChatGPT 4.5 del costo esorbitante delle sue API e una possibile ragione.

La Gragnuola di News
Qualche notizia su ChatGPT 4.5 & 5
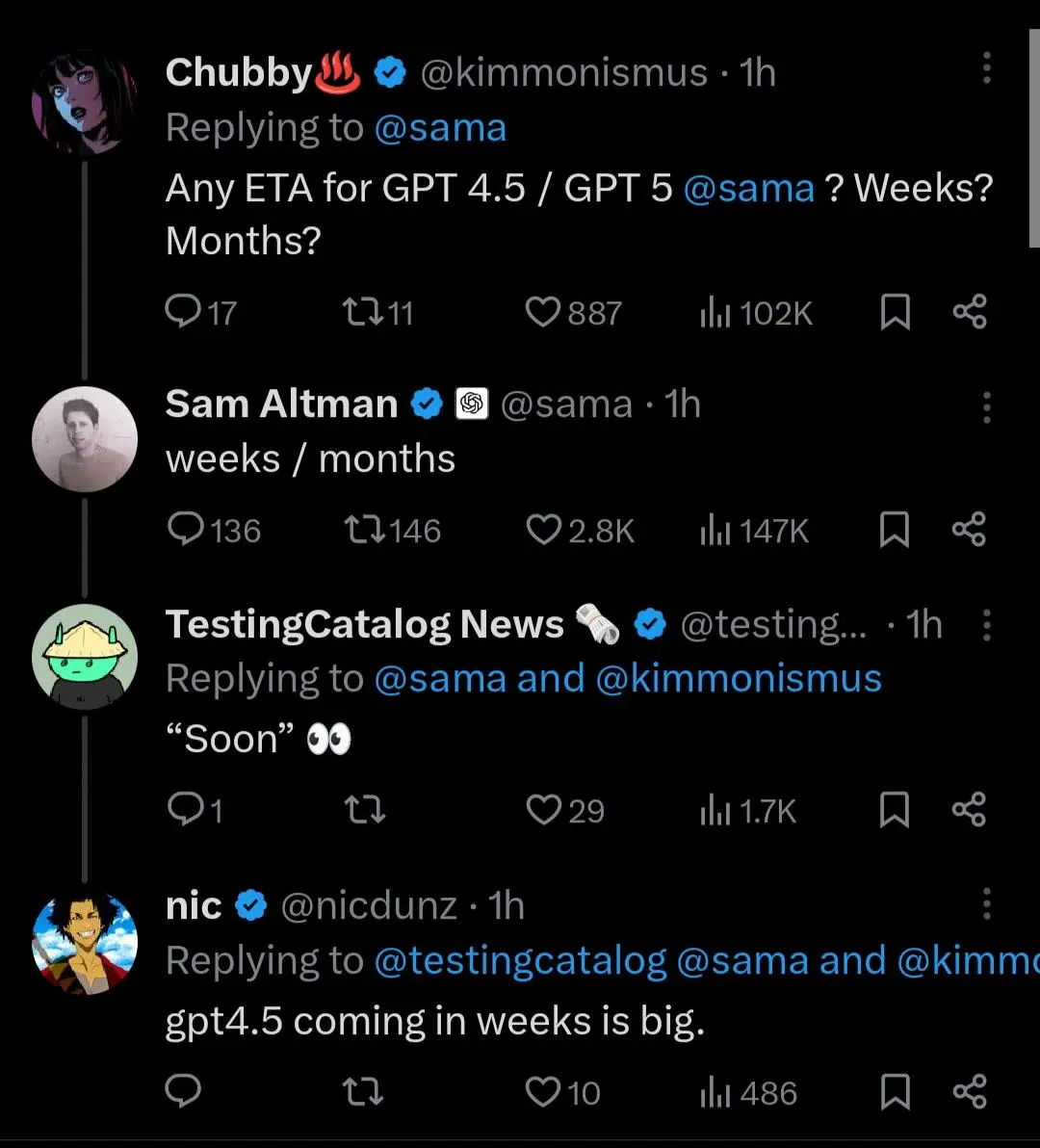
Sam Altman ha detto che ChatGPT4.5 uscirà a breve e sarà l'ultimo modello senza catena di pensiero. Ha anche aggiunto che in futuro sarà direttamente ChatGPT a decidere quale modello utilizzare. Non è il primo chatbot che sceglierà quale modello scegliere in autonomia.
Tra quando ho postato questa news e l'uscita dell'articolo abbiamo anche visto il rilascio di ChatGPT4.5
Abbiamo scoperto essere costosissimo, poco adatto alla programmazione, non avere una protezione dalle allucinazioni migliore di altri e generalmente non performare meglio di nessuno modello precedente. Fallimento quindi?
Fa una cosa molto importante: scrive in maniera ancora più naturale, capisce il contesto e riesce generalmente a mettersi meglio nei panni della persona (nel caso di role playing) in modo come nessun altro prima.
E' anche il primo modello della nuova generazione... quindi è un passo indietro su tutto ma è un tassello fondamentale di "ripartenza".
Orion da quanto sappiamo serve per generare Dati sintetici per i futuri modelli. Vediamo come saranno i prossimi modelli di ragionamento. Credo che il fatto che le API abbiamo un costo così alto sia proprio fatto per evitare che altri usino il sistema per allenare le proprie AI.


Grok 3 & Sonnet 3.7
Ammetto le mie colpe: non ho ancora provato nessuno dei due. Entrambi promettono grandi risultati nella programmazione ed entrambi hanno distrutto tutti i benchmark precedenti.
A me, che forse sono più Aestetic, mi ha colpito molto la cura di Anthropic nella presentazione del modello e la totale mancanza di stile di Grok. Vi lascio le immagini e i link.
Link
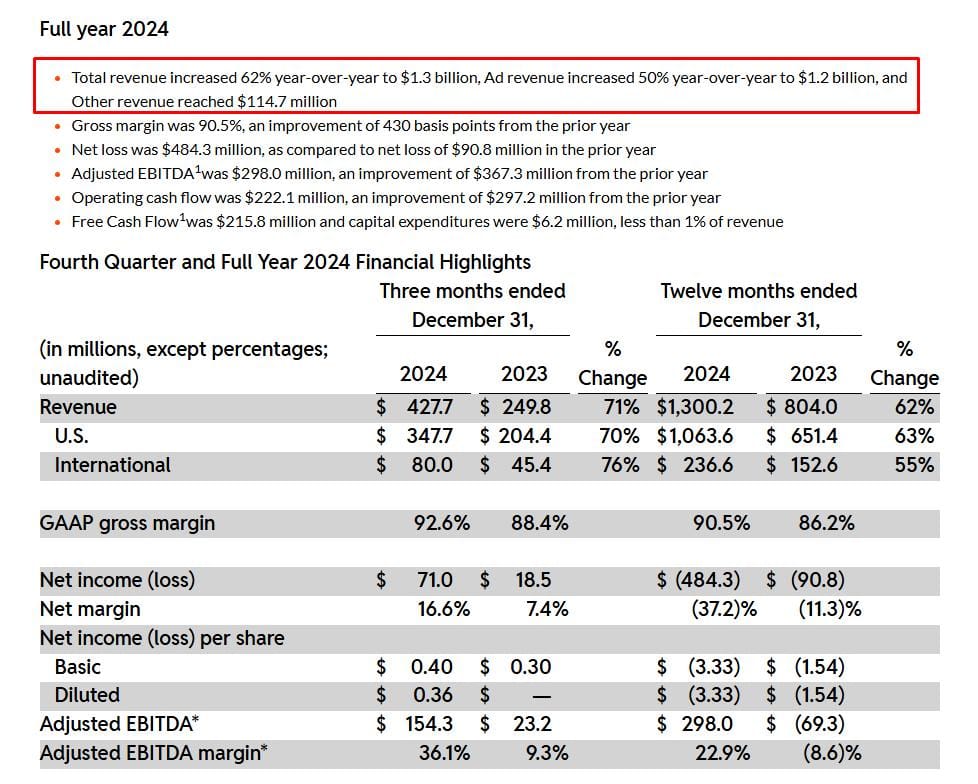
Reddit ci dice da dove arrivano i ricavi.
qualche giorno fa il CEO di Reddit (altro social di cui continuo a parlarvi) ha fatto un domanda e risposte: oltre ai contenuti dietro paywall ha anche condiviso i ricavi del 2024, dicendo che circa il 10% sono dovuti alle licenze che per sfruttare i contenuti della piattaforma.
Facendo due conti spannometrici: il 10% di 1.3B è 130M. Sappiamo che Google ha pagato circa 60M per le addestrare Gemini... I rimanenti 70M chi sono?
Non credo di sbagliarmi nel dire che l'acquirente è uno dei due tra OpenAI e Claude. Interessante.
Nota a margine: Vuoi vedere che il mio consiglio di scrivere contenuti su reddit di tempo fa può rivelarsi utile anche per fare ranking sulle AI? :-)
Solo l'1% del traffico di youtube arriva dai motori di ricerca.
Lo dice l'avvocato John Schmidtlein durante il processo per monopolio di Google intentata da Rumble. Su cosa sia Rumble ne parliamo un'altra volta (piattaforma alt right americana). Non so quanto sia vero il dato ma spero che in tribunale portino dei dati reali. Questo vuol dire che il 99% del traffico di Youtube è dovuto a link interni, algoritmo, hook e immagini di anteprima.
La domanda è quindi: Quanto tempo stiamo dedicando a questi ultime due variabili, che sono quelle su cui abbiamo più controllo?
L'universo è sempre pieno di sorprese
Un mondo così caldo e così vicino al sole che le nuvole sono fatte di metallo vaporizzato dove piovono zaffiri e rubini liquidi. Ha dei venti di ferro liquefatto che soffiano più velocemente della rotazione del pianeta.
No non sto parlando ne del centro di Milano in Agosto e nemmeno della trama di un romanzo Progressive Fantasy, bensì di un pianeta, Tylos, che è stato esaminato utilizzando i telescopi dell'Osservatorio Spaziale Europeo in Cile.
Ne parlando su Science Alert. Cosa centra questa news con la trasformazione digitale? nulla. Ma siamo un popolo di sognatori e viaggiatori.
Usare il DNA per infettare di codice malevolo una macchina?
Il futuro del Cyberpunk è già il presente. L’articolo di Nature mostra come degli aggressori possono nascondere un Trojan in una sequenza di DNA sintetico, codificando indirizzo IP e porta per stabilire una connessione remota e prendere il controllo del sistema. Per evitare il rilevamento, i dati vengono mascherati per somigliare a DNA autentico.
Tuttavia, il Deep Learning permette di individuare questi attacchi con un'accuratezza vicina al 100%, anche con tecniche avanzate di offuscamento. La fattibilità dell’attacco è stata confermata con un test in laboratorio.
Link:
Amazon cambia le regole dei download sul kindle.
Parlano di scenari Cyberpunk. Amazon qualche giorno fa ha cambiato il regolamento e i libri che hai comprato sul kindle non sono più proprio comprati, ma solo presi in prestito a tempo determinato. Chi mi segue sui social ho postato anche come fare a scaricarli prima che entrasse in vigore questo cambiamento.
Domanda: Come è vivere nel prequel di Neuromante x 1984 x Fahrenheit 451 ?
OK, anche questa settimana il mio desiderio di non inseguire le notivà dell'ultimo mi ha fatto buttare via un terzo degli articoli che erano scaduti 😄
Spero che tu gradisca questo mio sforzo. Se è così, condividi questa newsletter con 5 amici e colleghi. Ti odieranno un po' meno.
un abrazo,
Manolo





Member discussion