Mak's File - Episodio 31.2023

We are back, ci siamo presi una decina di giorni di pausa nel pubblicare la newsletter: si sono accumulate un po' di notizie, ma mi ha anche permesso di fare una selezione diversa dal solito. Continua il mio palleggiare tra l'approfondimento e il riportare le notizie brevi. Non ho trovato ancora l'equilibrio che mi soddisfa al 100%, ogni volta sistemo qualcosa. Mi sono preso anche un microfono degno di questo nome: probabile che inizi a fare degli short verticali per propagare il verbo.
Questa settimana iniziamo con articolo di Debunking sul fallimento prossimo venturo di OpenAI, un'altra notizia sulle AI e il medicale, la spinta per bilanciare la piega for-profit che hanno preso le AI. Chiudiamo le danze con un prompt che funziona benissimo anche su Bard
Ciao, Il mio nome è Manolo Macchetta e ti do il benvenuto ai Mak's File. Ogni settimana leggo decine di pagine di contenuti su Digital Transformation, Digital Marketing, AI & dintorni e te li ripropongo in questa newsletter.
OpenAI fallirà nel 2024. Ma è davvero così?Piccolo Articolo di Debunking

Sta girando da qualche tempo la notizia che OpenAI andrà a gambe all'aria già entro il 2024.
In molti la riportano: nessuno però si è preso la briga di andare a leggere l'articolo originario (se non per fare copypasta ovviamente).
Lo faccio io per te, che sei appena tornato dalle vacanze e hai il cervellino ancora bello rilassato.
L'articolo appare sul AnalyticsIndiaMag per mano di Mohit Pandey. La veridicità dell'articolo lascia un po' il tempo che trova secondo me.
L'autore prende i dati da similar web (sito che estrapola il numero di utenti, ma che non ha pretese di veridicitò) per dare il numero dei visitatori, da qui trae delle conclusioni piuttosto fantasiose sulla redditività dell'azienza...
Per esempio non vedo come un calo degli utenti Gratis e sia correlato col fallimento.
Non comprendo nemmeno l'anno che ha deciso di scegliere per dare una data di fallimento, al di la del titolo clickbait ovviamente. Perchè dovrebbe fallire entro il 2024? mi sembra un numero buttato li a caso.
Anche se fosse ancora vero che OpenAI perda 700K $ al giorno (potrebbero essere di più, ma anche di meno...) quanto fa questa cifra moltiplicata 365 giorni? 255 Milioni.
Open AI perderebbe 255M all'anno... tantissimi, ma
- Come sono i trend di incasso?
- Quanto vale la supremazia in un settore così caldo?
- Per quanto tempo è coperta grazie all'investimento di Microsoft?
L'articolo non risponde a nessuna di queste domande.
OpenAi vs Open Source.
Procediamo ancora un po' l'autore dice
"So, instead of going for what OpenAI offers, which is a paid, proprietary, and restricted version, why would people not go for an easily modifiable Llama 2?"
Ovvero: "Quindi, invece di scegliere quello che offre OpenAI, che è una versione a pagamento, proprietaria e limitata, perché le persone non dovrebbero scegliere un Llama 2 facilmente modificabile?".
per quanto io spinga dal mio blog la scelta Opensource per le AI generative e spero che quello sia il futuro. quanti di noi hanno LLama 2 installato sul computer ? Quanti di questi hanno creato e utilizzato una propria AI grazie a LLama?
Immagino che nel lungo periodo molti player utilizzeranno la soluzione Open, ma il 2024 è il prossimo anno. La data mi sembra davvero poco verosimile.
Chiudo qui la piccola critica: bravo Mohit Pandey che con un articolo click bait è riuscito ad andare virale, ma tirata di orecchie a tutti i siti di news che hanno riportato la notizia senza controllare.
Diabete, Radiografie & AI

Sul sito della Emory University si parla dello sviluppo di un modello di Deep Learning rileva il diabete utilizzando le radiografie del torace.
Radiografie? Per il diabete? fammi fare un passo indietro.
Come funziona al momento
Negli Stati Uniti le attuali linee guida suggeriscono di sottoporre a screening per il diabete di tipo 2 i pazienti di età compresa tra i 35 e i 70 anni e con un indice di massa corporea tra il sovrappeso e l'obesità.
Molti studi, tuttavia, hanno riscontrato che questa strategia non tiene conto di un numero significativo di casi per i quali l'IMC è un fattore predittivo meno efficace del rischio di diabete.
I pazienti con diabete non diagnosticato sono a rischio molto più elevato di complicanze della malattia, tra cui danni irreversibili agli organi e ovviamente la morte.
I ricercatori hanno sviluppato quindi un modello in grado di segnalare con successo un rischio elevato di diabete in un'analisi retrospettiva, spesso anni prima che ai pazienti venisse diagnosticata la malattia.
Ogni anno, milioni di americani si sottopongono già a radiografie del torace per dolori al petto, difficoltà respiratorie, lesioni o prima di interventi chirurgici. La sola Emory esegue in media circa 200.000 radiografie all'anno.
I radiologi non cercano il diabete quando valutano queste radiografie, ma le immagini entrano a far parte della cartella clinica del paziente e potrebbero essere comunque analizzate per individuare altre condizioni.
Un'alternativa opportunistica
"Le radiografie del torace rappresentano un'alternativa 'opportunistica' al test universale per il diabete", afferma Judy Wawira Gichoya, MD, assistente alla cattedra di radiologia e scienze dell'immagine e ricercatrice principale dell'Emory.
Il modello di intelligenza artificiale è stato addestrato su oltre 270.000 radiografie di 160.000 pazienti e il deep learning ha determinato le caratteristiche dell'immagine che meglio predicevano una successiva diagnosi di diabete.
Funziona? Siamo ancora alla finestra ma ci sono speranze
Quando il team dell'Emory ha applicato il modello a un gruppo separato di quasi 10.000 pazienti, ha scoperto che il modello prevedeva il rischio meglio di un semplice modello basato solo su dati clinici non legati all'immagine.
Superata questa prima fase di test il team di ricerca è al lavoro su come convalidare il modello e incorporarlo nei sistemi di cartelle cliniche elettroniche: questo permetterebbe di fornire ai medici un avviso per proseguire lo screening tradizionale in base ai risultati delle radiografie.
Se i risultati finali confermano quelli preliminari lo studio verrà allargato per diagnosticare altre condizioni mediche.
CREATE AI Act

Lo mese scorso, in sordina, entrambi i rami del Congresso degli Stati Uniti hanno presentato una nuova proposta di legge potrebbe dare un grosso impulso alle AI no-profit.
La proposta di legge è chiamata CREATE AI Act e nei piani è di istituire una risorsa nazionale per la ricerca sull'intelligenza artificiale, in grado di fornire l'accesso al pitere di calcolo e ai dataset tanto necessari a studiosi, ricercatori no-profit e startup.
Stanford sta facendo pressioni al governo per ratificare la proposta di legge il prima possibile.
My Two cents
Questa proposta di legge è necessaria per il futuro dell'IA e dovrebbe esserci qualcosa di simile anche in Europa. Il motivo è chiaro e l'ho ribadito più volte: c'è uno squilibrio preoccupante nel controllo dell'IA.
Solo le aziende più ricche - Google, Microsoft, Amazon, Meta hanno il budget e i dati per impegnarsi sul lungo periodo in questo sviluppo ricerca. Il recente arrivo di AI in opensource è di sicuro un segnale incoraggiante, ma da solo non basta.
Il fatto che le AI vengono sviluppate per profitto è una sovra-struttura importante. I laboratori accademici, per quanto siano anche improduttivi alle volte, pensano in modo più ampio, con orizzonti temporali più lunghi, ma vengono completamente esclusi da questa corsa.
Questo limita l'ecosistema dell'innovazione dell'IA. Per fare un esempio: negli Usa, nel 2022, ci sono state 32 scoperte industriali nell'IA, solo tre nel mondo accademico e nessuna nel governo.
Se diventa legge la CREATE AI porterà un maggior numero di stakeholder diversi alla partita. Esempi illustri precedenti ne abbiamo: Internet, GPS e più recentemente CRISPR.
La Germania vuole combattere la recessione con un investimento massiccio nelle AI
Parlando di Nazioni che vogliono spingere sulle AI: ho trovato questo grafico, che non è perfettamente allineato con i numeri di Our World in Data, ma che comunque è verosimile.
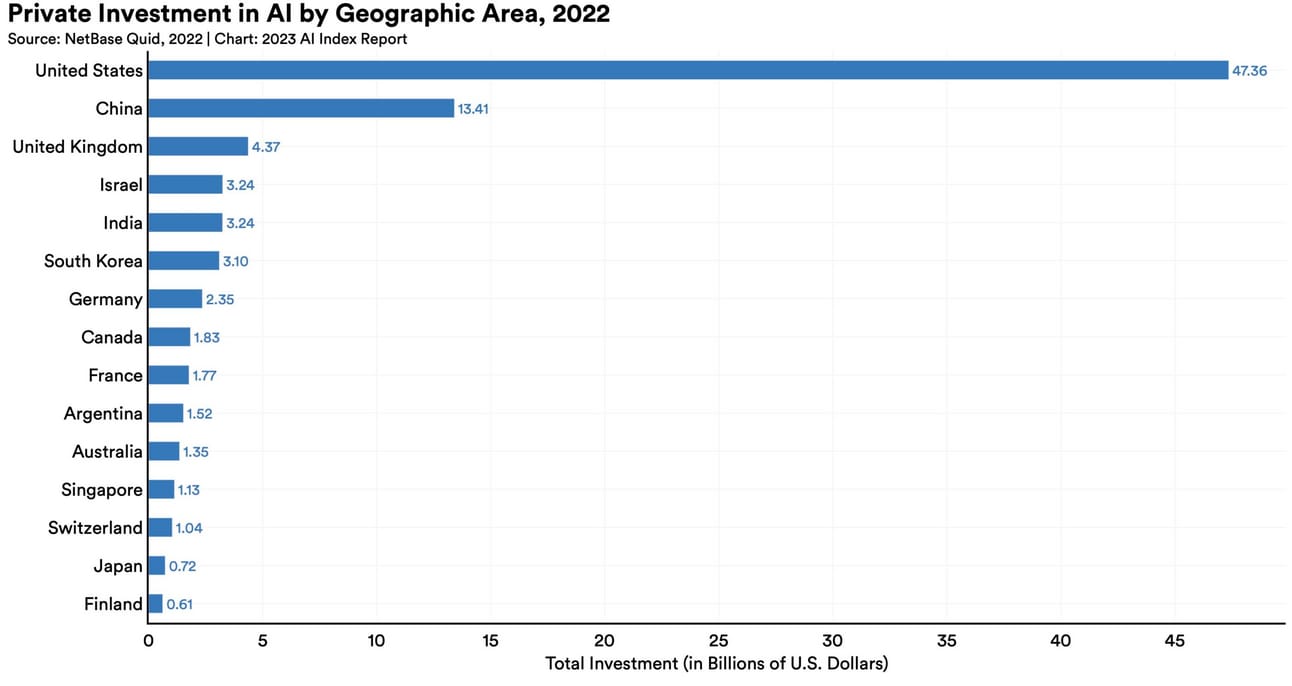
La Germania prevede di investire (con finanziamenti pubblici) un ulteriore miliardo di euro nella ricerca sull'IA nei prossimi due anni, questo perchè colpita dalla recessione non vuole perdere il passo verso altri attori.
La strategia è di aprire circa 150 laboratori universitari di ricerca. Ottima notizia, questo potrebbe essere il primo passo per una strategia europea sulle AI che non pensi solo a vietare ma anche a fare crescere.
La Gragnuola di News

Dato che nel primo articolo può sembrare che abbia sminuito l'importanza che do all'opensource, ti riporto 3 notizie che sottolineano l'importanza dello sviluppo delle AI in ambienti aperti.
ToolLLM - API per gli LLM Opensource. In un paper uscito settimana scorsa ( ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs ) si cerca di risponde a una delle limitazioni più pesanti dei LLM open-source, (LLaMA e Vicuna su tutti), ovvero la capacità di interagire con strumenti esterni tramite le API. Ciò contrasta con gli LLM come ChatGPT, che invece hanno sempre più integrazioni per tali compiti.
Meta ha presentato Code Llama, uno strumento basato sul suo modello linguistico Llama 2, progettato per la generazione e il debug di codice. Disponibile con la stessa licenza di Llama 2, Code Llama può creare stringhe di codice e persino comprendere istruzioni in linguaggio naturale. Meta sostiene che Code Llama ha ottenuto buoni risultati nei test di benchmark, ma non ha specificato i modelli con cui è stato testato. Lo strumento mira a migliorare i flussi di lavoro e l'efficienza degli sviluppatori. Meta prevede di rilasciare tre dimensioni di Code Llama, per soddisfare le diverse esigenze dei progetti.
Chiudiamo il trittico di News sull'Open Source: Hugging Face, che è il sito che raccoglie tutti i modelli Opensource delle AI, ha raccolto 235 milioni di dollari in un round di finanziamento di serie D, portando la sua valutazione a 4,5 miliardi di dollari. Il round di finanziamento è stato guidato da Salesforce Ventures e ha visto la partecipazione di grandi colossi tecnologici come Google e Nvidia.

Google presenta NotebookLM, una AI che guarda nei tuoi appunti e fa quello che un LLM dovrebbe fare: riassume, da spunto e molto altro. Solo in USA, solo in waitlist, ma quando esce da noi potrebbe diventare in pochi istanti l'APP che metto che utilizzerò.
- Lo trovi qui: https://notebooklm.google/
- Se vuoi far leggere i tuoi appunti da ChatGPT, qui ti spiego come: https://manolo.macchetta.com/come-far-leggere-i-propri-appunti-e-libri-a-chatgpt/
Parliamo ancora di Chip, Nvidia rivela un nuovo chip A.I. e afferma che i costi di gestione dei LLM "diminuiranno in modo significativo".
Il GH200 di Nvidia ha la stessa GPU dell'H100, l'attuale chip AI di fascia più alta di Nvidia, ma la abbina ai 141 gigabyte di memoria all'avanguardia un processore centrale ARM a 72 core. H100 secondo alcuni benchmark già tagliava dalle 5 alle 10 volte i costi di allenare una AI.
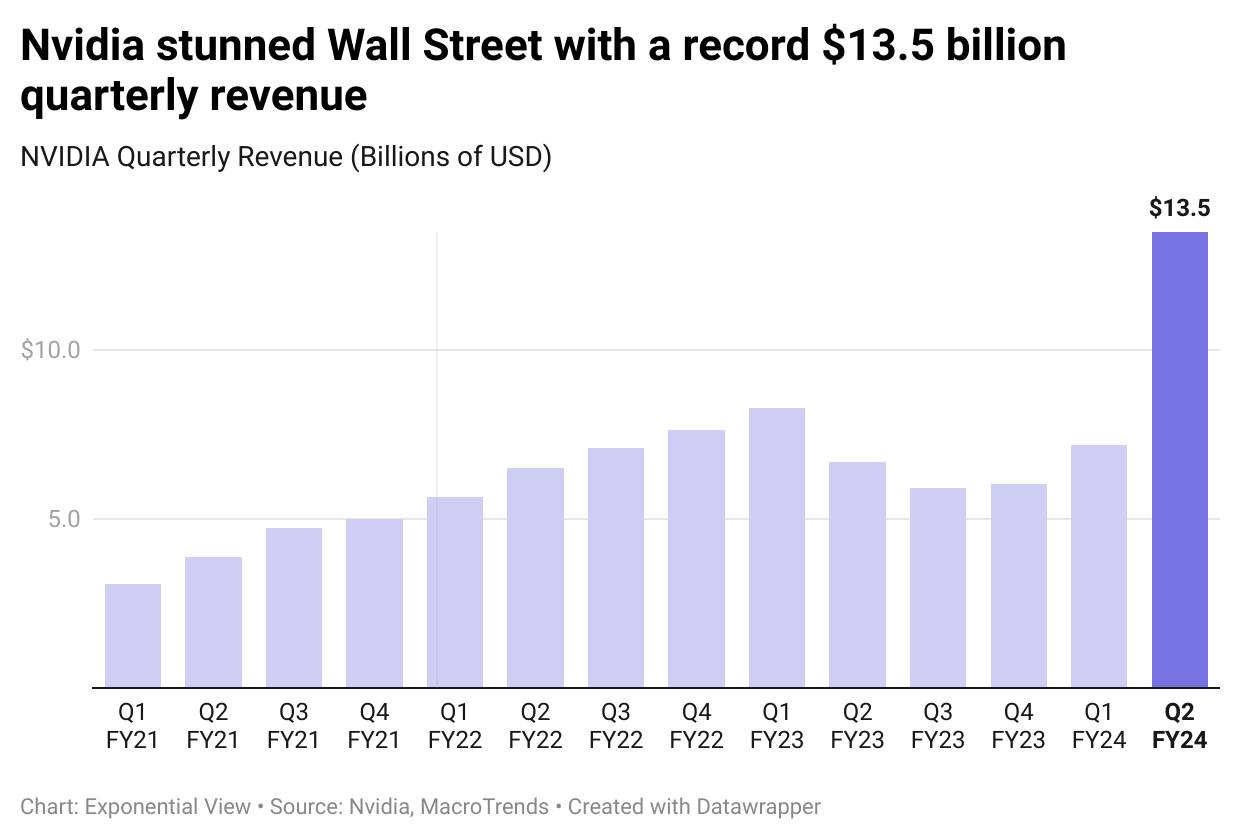
Sempre Nvidia ha chiuso il trimeste con un record di ricavi stupefacente anche nelle già rosee aspettative dell'azienda, lascio un grafico, che vale mille parole
Il recente cambio dei termini di servizio di. Zoom sembravano consentire all'azienda di utilizzare liberamente i dati dei clienti per addestrare i propri modelli di apprendimento automatico, ma dopo le polemiche, nella tarda serata di lunedì, Zoom ha aggiornato i propri termini per specificare che "Zoom non utilizzerà contenuti audio, video o chat dei clienti per addestrare i nostri modelli di intelligenza artificiale senza il vostro consenso". La faccendo dei dataset è sempre più complessa. L'equilibrio tra la protezione della privacy dei clienti e l'utilizzo ottimale dei loro dati sarà sempre più messo a rischio.
Google Analytics su Google Docs. Come sai a luglio siamo passati a GA4. Il passaggio non è proprio stato indolore per tutti. Google ha rilasciato questa settimana un add-on per fare i report di GA4 anche Google Sheet. Finalmente! lo trovi qui.
Il prompt che funziona bene anche su Bard

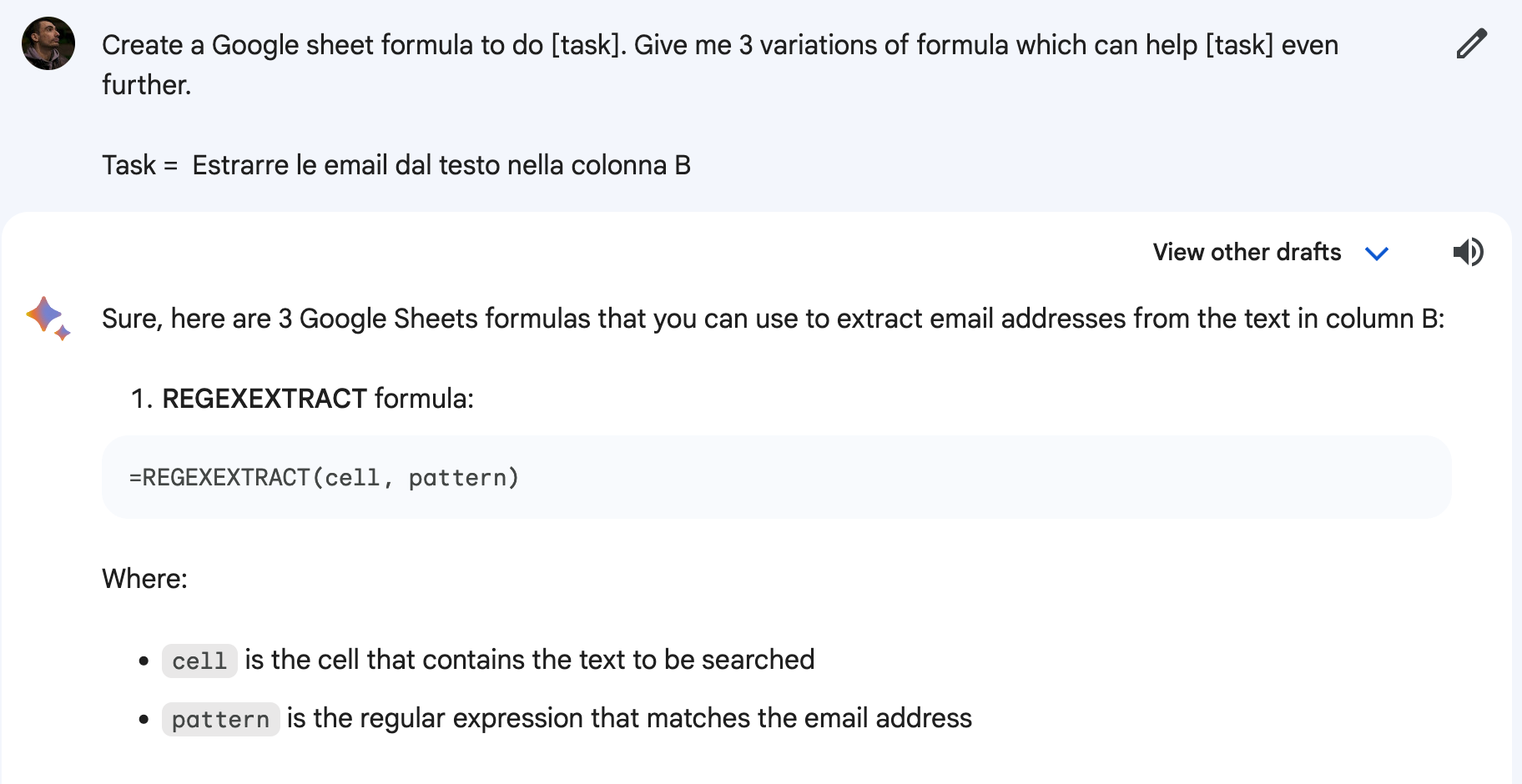
Era un bel po' che non trovavo un prompt utile davvero. Questo che ti propongo oggi è decisamente interessante... non sempre le 3 variazioni richieste funzionano tutte, ma le ho provate sia su ChatGpt che Bard... e quest'ultimo mi sembra molto più sul pezzo
Create a Google sheet formula to do [task]. Give me 3 variations of formula which can help [task] even further.
Task = [Insert here]
Questa Newsletter ha risentito un po' della pausa forzata: questi dieci giorni ho raccolto notizie disparate e ho dovuto riportatarne un po' troppe, senza dargli una direzione univoca, ma come dicevo in apertura sono ancora alla ricerca dell'equilibrio. Sappi che anche l'episodio 32.2023 è quasi fatto :-)
Abrazo,
Manolo





Member discussion